It’s been three months since I switched from my Paperport-based electronic scanning/filing system to a combination of NAPS2, PDFgear, and paperless. So how’s it going? It took me a little while to get used to using three separate applications instead of one, but now I actually like that I’ve decoupled all the various functions into separate pieces of software that I can swap out and replace easily (if needed).
NAPS2
I have nothing bad to say about NAPS2. Once I had my different profiles set up, scanning was a snap. The only issue I had was that TWAIN scanning stopped working when I finally uninstalled Paperport. Of course, this wasn’t the fault of NAPS2 and instead I switched to eSCL scanning and it works great (if not better). I use the basic tools in NAPS2 to crop and rotate my scanned documents, and then load them up into PDFgear if they need a little more TLC.
PDFgear
I really only have one complaint about PDFgear: it doesn’t really support multiple monitors. By that I mean it won’t remember what monitor I last closed it on, so it always opens on my primary screen. It’s a minor issue, and I reported it to the developers (who said they would fix it in a future release), but it’s annoying nonetheless. PDFgear also doesn’t support MDI so each PDF document opens in its own separate window instead of a tabbed interface like Acrobat (okay, I guess that’s two complaints but I actually don’t mind the lack of MDI too much).
UI aside, using PDFgear to “stack” PDF documents is my primary use case and it’s pretty easy to do. I’ve also had no issues with the occasional need to annotate. It’s a solid app and I recommend checking it out.
paperless-ngx
This was a big change (obviously). After wrapping my head around paperless’ “consumption” model (where it takes a document from a specified watched location and then moves it into its own file structure), I had to figure out how (if) I wanted to replicate my existing filing folder setup rather than using the default “flat” structure (which means you end up a single folder of files named things like “0000123.pdf”). The setup I’ve been using for the past 25 years looks like this:
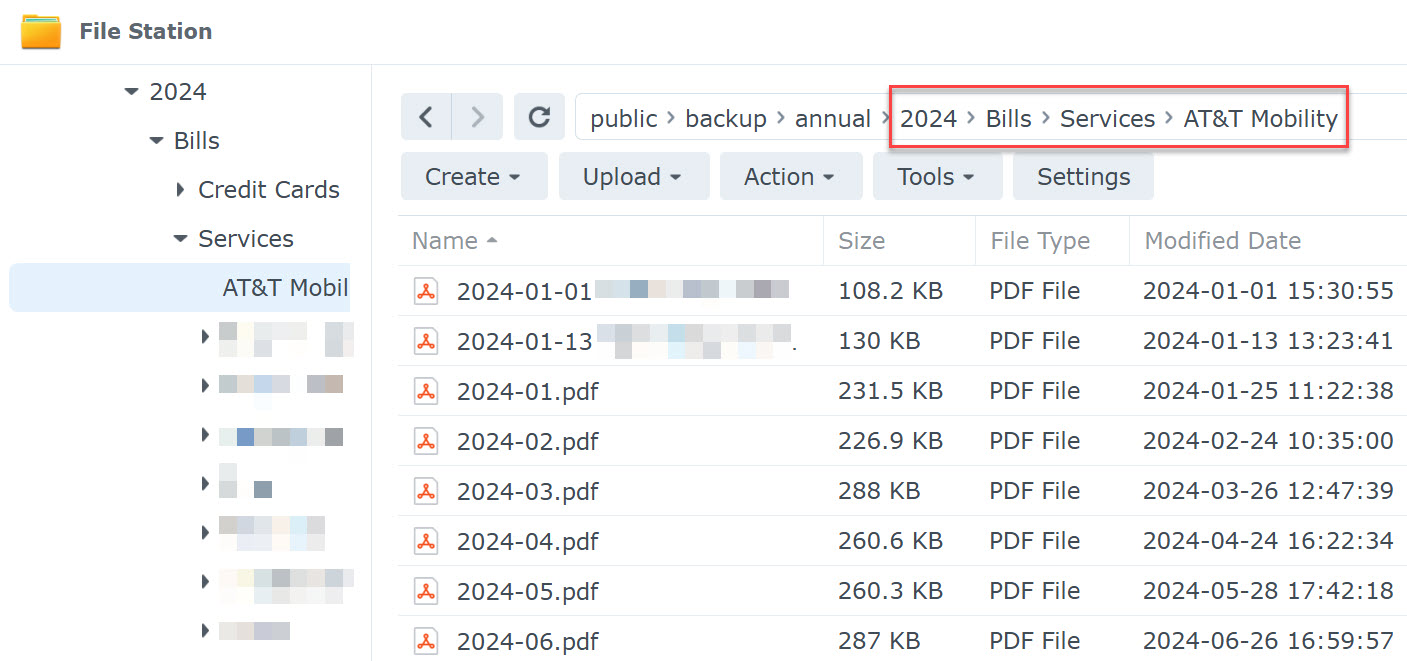
original folder structure
Basically one folder for year each, the a sub-folder structure of type (bills, receipts, cars, etc.) then more sub-folders for types, entities (like Chase, AT&T, the lawn service guy), etc. To achieve something similar in paperless, I set PAPERLESS_FILENAME_FORMAT={{ created_year }}/{{ document_type }}/{{ correspondent }}/{{ title }} in the config. That gave me this:
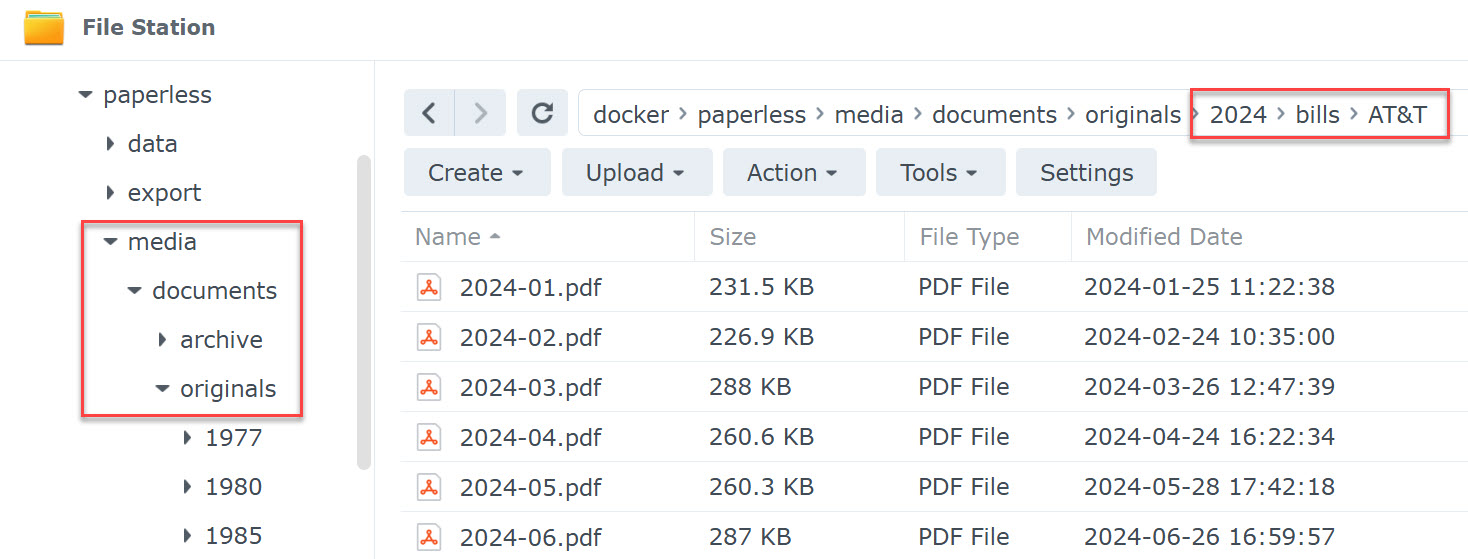
paperless folder structure
Which is pretty close. While it’s not an exact match to my (admittedly personal) hierarchy, it’s still generally browsable by a person outside of the paperless UI. Notice, for example, the two files at the top of the list in the “original” screenshot that are missing from the new screenshot. Those documents were not “bills” so they ended up in a different folder in the paperless hierarchy (originals/2024/receipts/AT&T). There’s also a more advanced concept of storage paths (which effectively allows for multiple PAPERLESS_FILENAME_FORMAT settings with rules around them), but for now I’m sticking with the single format setup.
For all of that to work, of course, you need to define your document types, correspondents, and tags. For my conversion process, I basically copied one folder at a time into the paperless consumption directory and then once the documents were processed, went into the UI and used batch updates to add the appropriate attributes (I also experimented with using the PAPERLESS_CONSUMER_SUBDIRS_AS_TAGS setting, which converts subfolders in the consumption directory into tags, but since some of my folder structure included the correspondent, that didn’t work perfectly (I didn’t need AT&T to be a tag, for instance)). Here’s an example of some of that setup:

document types, correspondents, and tags
I also had to tweak how paperless processes dates: when it OCRs a document, it looks for the first date on the page to use as the “created date” (as opposed to “added date”). The default PAPERLESS_DATE_ORDER is DMY so I changed that to MDY. I also set PAPERLESS_IGNORE_DATES to ignore special dates like birthdays so those wouldn’t be used as creation dates.
As I proceeded with the conversion, paperless started “learning” and got progressively better at auto-assigning document types, correspondents, and tags, but then it soon became apparent that my choice of using SQLite as the back-end database was ill informed as performance was starting to suffer (and I was getting a lot of 500 internal server errors). That took me on a short side quest to switch over to MariaDB. By this point I had done enough work that I didn’t want to start over so I deployed a new paperless container using MariaDB (in another container) as the back-end, did a “data only” export from the old SQLLite paperless-ngx setup using the document_exporter, and then imported it into the new empty MariaDB database with the document_importer. Then it was just a matter of shutting down the old paperless container and pointing the new one to the same folder location. The new setup was noticeably faster, especially when during full-text searches (I actually ended up moving all of my MySQL databases into the MariaDB container and even converted my Vaultwarden database from SQLite).
Once the infrastructure setup stabilized and I had paperless configured more or less the way I think I wanted it, I continued with the conversion and cleanup. I had a lot of manual cleanup to do, not surprising since I was bringing in 25 years of document history. For the most part this involved doing creative searches to get a result set of common documents and then bulk editing to set the proper document type, correspondent, and any tags.
current stats
I just finished all of that cleanup at the end of January (I said it was a lot!) and I have to admit there were more than a few times during that when I wondered if this was all a waste and I was going to end up going back to Paperport. I’ve stuck with it, though, and did learn a few lessons along the way:
- There’s no need to dump everything into paperless. My 25 years of archives had a lot of things I didn’t need to consume into paperless: images, old work files, random text files, diagrams, etc. A big part of my cleanup was actually deleting stuff I had bulk consumed into paperless but didn’t really need. Only consume the things you need to index and search on.
- Figure out your document types and tags first (as much as you can, anyway). A few times during the conversion I realized I wanted to add a new tag and had to go back and find all the documents I had already processed and edit them again to make the new tag changes, which just meant extra work. Alternatively, learn about the various command-line tools like document_retagger.
- In a similar vein, plan our your file/folder hierachy before adding a lot of documents. Do you not care about browsing the files/folders outside of paperless and want to just stick with the flat default? Or come up with a clever naming convention? If you decide to make a change after you’ve started, you’ll need to run the document_renamer which will take your PAPERLESS_FILENAME_FORMAT and go through all of your documents and rename to match the new format, which can take a long time. There are also command-line utilities to regenerate the archive (OCR’ed) versions of your consumed files, but the more you have things planned out ahead of time, the better.
- If you don’t need to audit every change made to a document in paperless (i.e., you’re not running this in some sort of office setting where that would be important), turn off audit logging via
PAPERLESS_AUDIT_LOG_ENABLED=false. After I finished my conversion and cleanup, the auditlog_logentry table in the database was over 1gb! After turning off audit logging and dropping the table, my paperless database went down to a more manageable 250mb (remember that’s just the database storing the metadata, it doesn’t include the actual files in the paperless media folder, which for me is 18gb (and that’s after I cleaned out a ton!).
Obviously if you’re starting from scratch, some of those don’t apply. Happy filing! 🙂
Since finishing the setup I’ve started exploring some of the other features of paperless-ngx, like automatically consuming PDF attachments from my e-mail (which saves some steps of saving the attachment and then copying it into the consume folder for paperless to process). I’ve also been playing around with Swift Paperless on iOS, a mobile app that connects to paperless. It’s handy for looking up documents from my phone. Of course, this is only useful if you’ve either exposed your paperless installation to the internet (and I did try that for a while, even set up SSO through Github) or can VPN into your home network while away to access paperless locally (which is what I do now).
I have to admit that I still haven’t made a complete break from my old filing structure. I’m still putting new documents into my “old” structure (new folder for 2025, of course!) and then also dropping a copy into the separate consume directory which loads it into paperless (and thus makes another two copies (the original and the archive) out on my NAS). At some point I might try to just stick with the paperless structure (maybe my 2026 project?) but 25 years makes a habit hard to break, even if it just bits on a disk.